
Este análisis lo realicé hace unos meses para uno de los módulos del curso de Estadística y Matemáticas aplicadas al deporte con R, de Sports Data Campus.
Lo que se propone en este ejercicio es hacer una comparación entre dos diferentes modelos de clusterización, uno no jerárquico y otro jerárquico.
Los datos utilizados son seleccionados por mí y obtenidos del portal web Fbref, basados en métricas ofensivas de la temporada 2022-2023.
SELECCIÓN DE LA MUESTRA
Antes de realizar cualquier paso en el algoritmo, tenemos que seleccionar la muestra con todos los datos que queremos que se tengan en cuenta. Este proceso es importante, porque dependiendo de lo que escojamos, el resultado de la clusterización variará.
Dado que los datos que tenemos corresponden a métricas ofensivas exclusivamente, restringiremos la muestra por posición, por minutos jugados, por ciertos campeonatos y por un número determinado de métricas:
- Posición: Delanteros.
- Minutos jugados: Igual o más de 2.500 minutos jugados.
- Competiciones: La Liga, Premier League, Bundesliga y Ligue 1.
- Métricas seleccionadas: Goles, xG, xG sin contar los penaltis, disparos, disparos a puerta, porcentaje de disparos a puerta y goles por disparo (todas las métricas siempre dadas por 90 minutos).
ESTANDARIZACIÓN Y VALORES ATÍPICOS
ESTANDARIZACIÓN
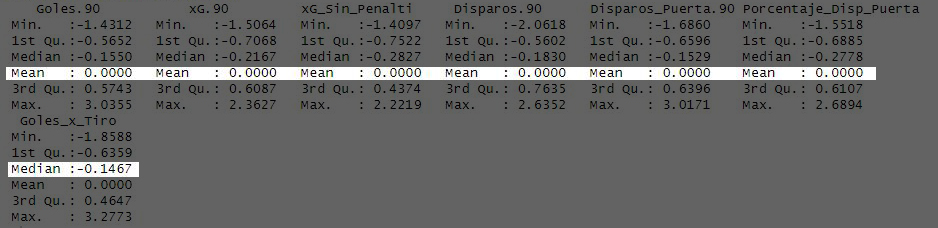
Una vez tenemos lista la muestra definitiva, el siguiente paso es estandarizar estas variables para evitar que una variable tenga más importancia que otra por el hecho de estar medidas en distintas magnitudes.
Esto se consigue haciendo que todas las variables tengan una media igual a 0 y la desviación estándar igual a 1.
VALORES ATÍPICOS
Encontrar los valores atípicos puede resultar fundamental para determinar las distancias, ya que pueden influir de manera destacada en el análisis que hagamos.
EVALUACIÓN DE TENDENCIA DE AGRUPAMIENTO
El último paso antes de comenzar con el análisis de clusterización será el de evaluar la muestra para saber si los datos son agrupables, es decir, ver si los jugadores del dataset tienen ciertas similitudes y ciertas diferencias que permitan hacer una buena segmentación.
Esto se consigue con el Estadístico de Hopkins:
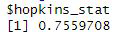
El Estadístico de Hopkins es un valor comprendido entre 0 y 1 y, cuanto más cerca esté el valor de 1, mayor sentido tendrá hacer clustering (en este caso, como el resultado es de 0.7559708, quiere decir que es óptimo para su realización).
ANÁLISIS DE CLUSTERIZACIÓN NO JERÁRQUICO: K-MEDIAS
Es el momento de aplicar el algoritmo para hacer la clusterización, y vamos a comenzar con el método no jerárquico K-Medias.
- Como es un algoritmo no supervisado, debemos decirle al algoritmo cuantos cluster nos interesa tener.
- ¿Cómo se determina el número óptimo de clusters? Una buena forma es aplicar la «Regla del codo».
- La curva que hace es la suma de errores cuadráticos dentro de los clusters y se elige el punto donde la curva tiende a estabilizarse.
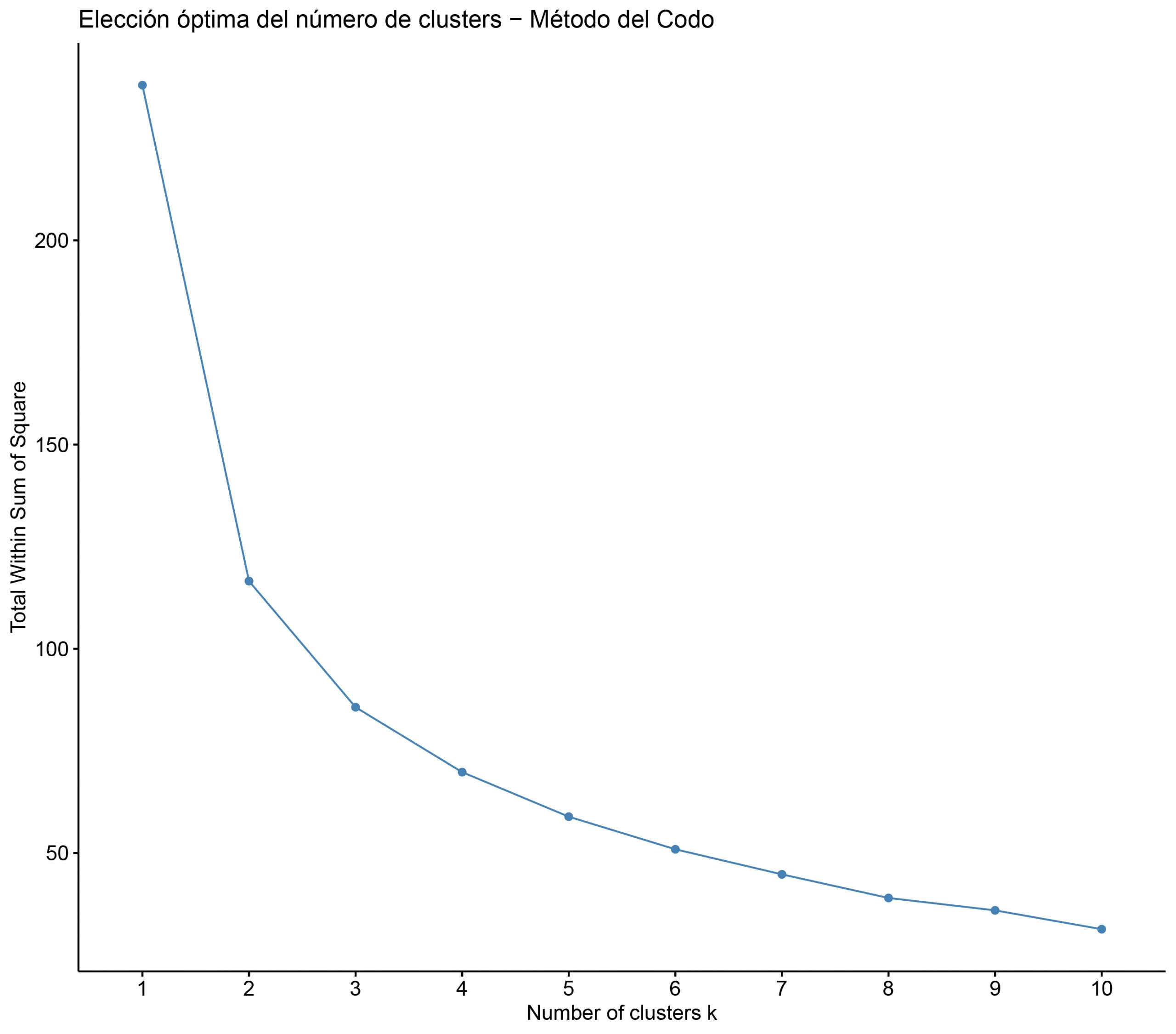
Vemos que según la regla del codo podemos determinar 3 como número óptimo de clusters.
Ahora, se aplica el algoritmo de clusterización y obtenemos el nombre de cada jugador de la muestra con el número de cluster al que corresponde:

Si aplico el análisis de componentes principales (PCA), usando solo las dos primeras dimensiones (que son las que mayor información aglutinan), podemos ver representada esta información en una gráfica:
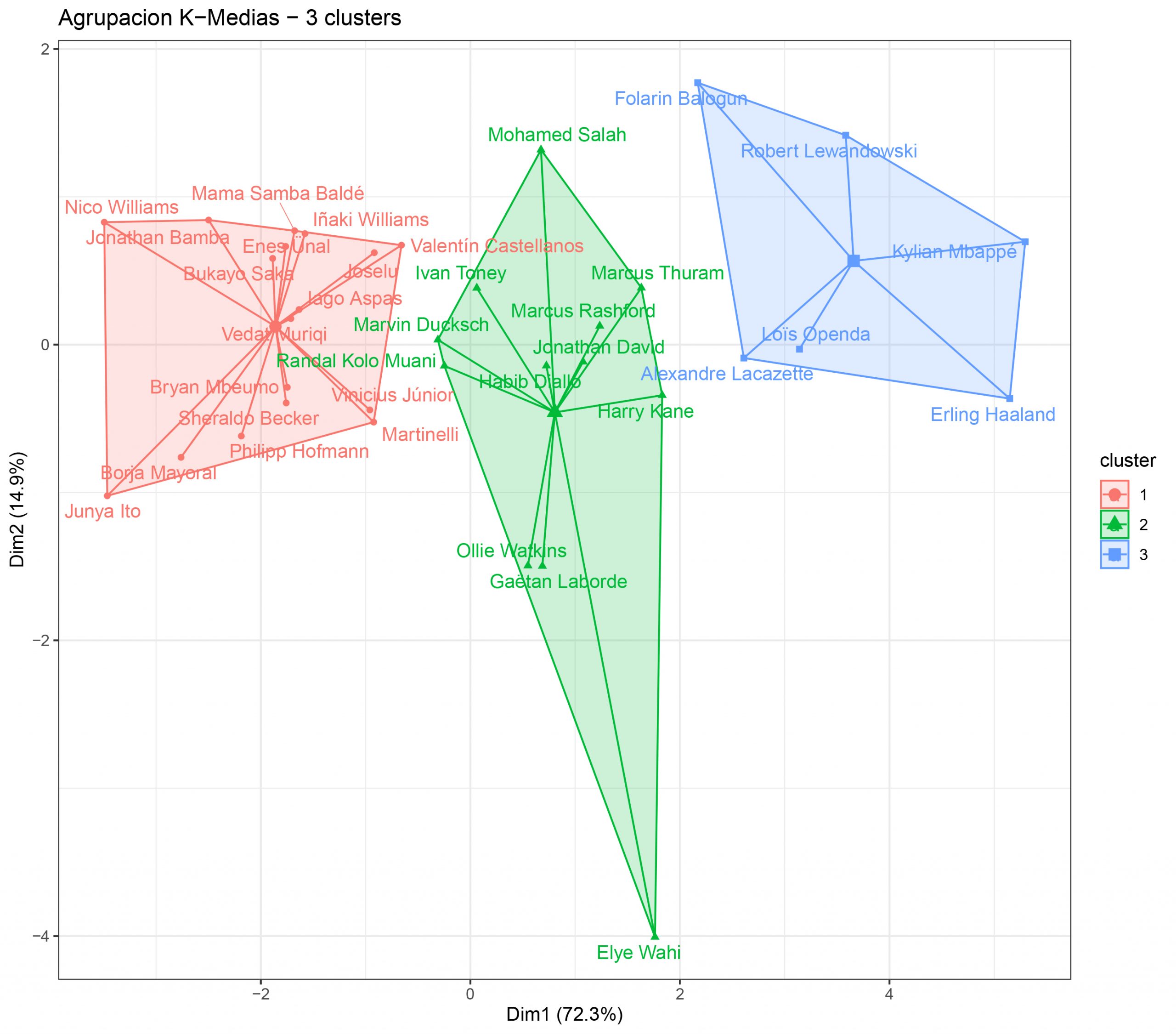
- Vemos 3 clusters, el número 1, formado por jugadores que juegan en su mayoría en equipos de calidad media-baja, donde sus estadísticas goleadoras pueden resentirse (el máximo goleador de este grupo es Joselu, con 16 goles).
- En el cluster 2 vemos ya jugadores con unas estadísticas goleadoras superiores y que militan en su mayoría en equipos más top, pero que no han tenido una temporada a la altura de lo que se esperaba, como Salah (19 goles, lejos de sus registros habituales), Marcus Rashford (17 goles) o Harry Kane (30 goles y una grandísima temporada a pesar del mal momento de su equipo).
- En el último cluster vemos, entre otros, a los máximos goleadores de La Liga (Lewandowski, 23 goles), Ligue 1 (Mbappé, 29 goles) y Premier League (Haaland, 36 goles).
También podría seleccionar solo un par de variables que considere importantes y hacer un gráfico de dispersión enfrentándolas.
Por ejemplo, me parece interesante ver quién es el delantero más eficaz, no el más goleador, sino el que necesita menos disparos para marcar más goles (siempre hablando por 90 minutos):
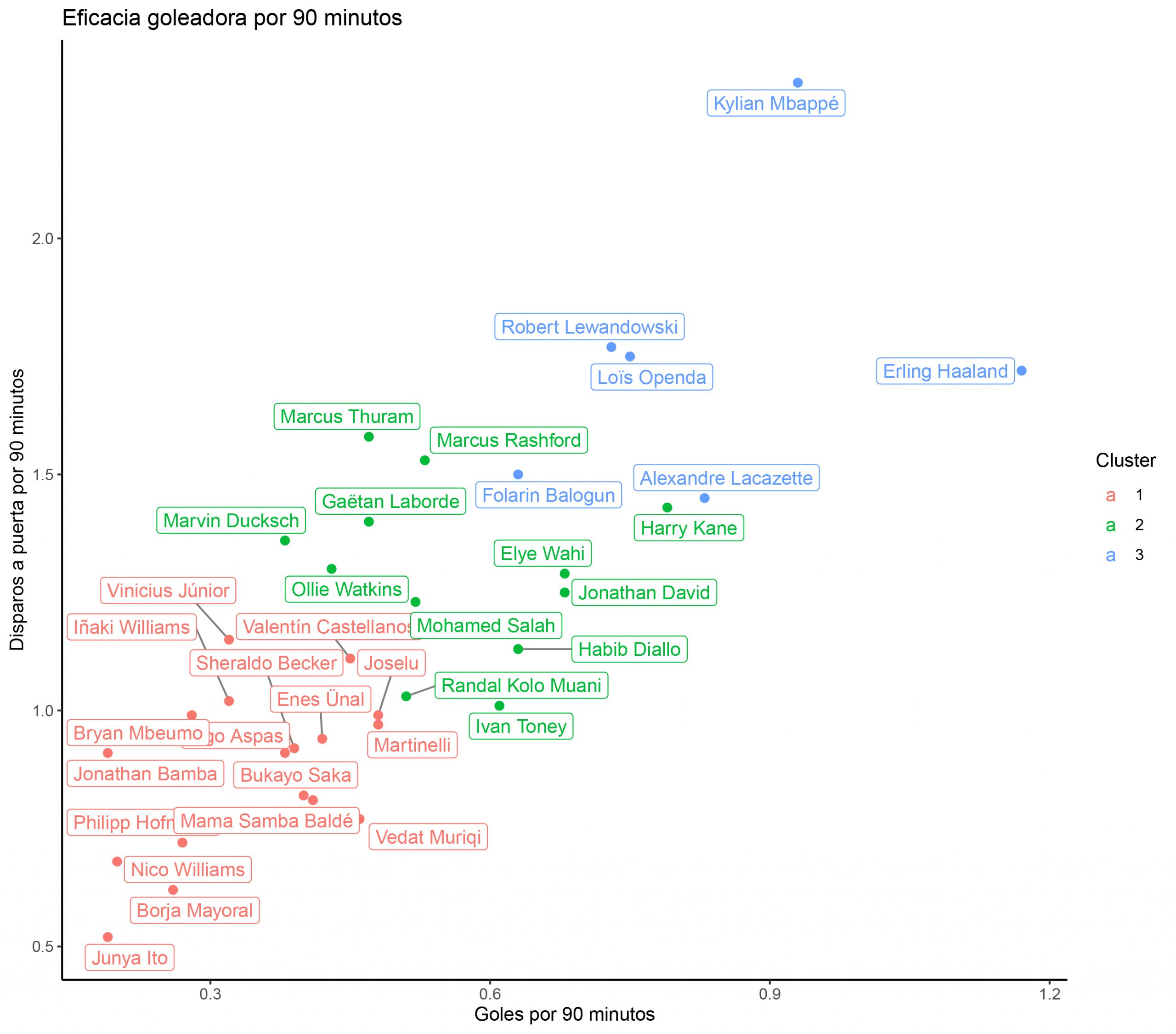
- Vemos como los clusters están bien definidos.
- Desgranando la información que el gráfico muestra, vemos que Haaland es, con mucha diferencia, el delantero que mejor relación tiene entre los disparos que necesita realizar con los goles que consigue, mientras que, por ejemplo, el otro crack mundial, Mbappé, necesita disparar mucho más para marcar gol.
- Por hacer una comparativa de Mbappé con el segundo máximo goleador de la Ligue 1, el gráfico nos muestra que a pesar de que Mbappé marca más goles por noventa minutos, Lacazette es más efectivo de cara a puerta, necesita menos disparos para marcar.
- Pero como en este gráfico estamos hablando de eficacia, observemos que hay jugadores del cluster 1, el de los llamados equipos de calidad media-baja, que también son eficaces, como por ejemplo Borja Mayoral o Nico Williams.
- Llama la atención que Vinícius esté también en el cluster 1, lo que indica que a pesar de haber mejorado enormemente en la finalización en las dos últimas temporadas, aún necesita generar muchas ocasiones para conseguir gol.
- Dicho todo esto, debemos tener en cuenta que cuantas más veces dispares a puerta, más difícil será mantener un porcentaje alto de eficacia.
EVALUACIÓN DE LAS PARTICIONES
Para finalizar, vamos a hacer una evaluación de las particiones que hemos hecho, es decir, vamos a ver qué tal están hechos nuestros tres clusters aplicando el método de la Silueta.
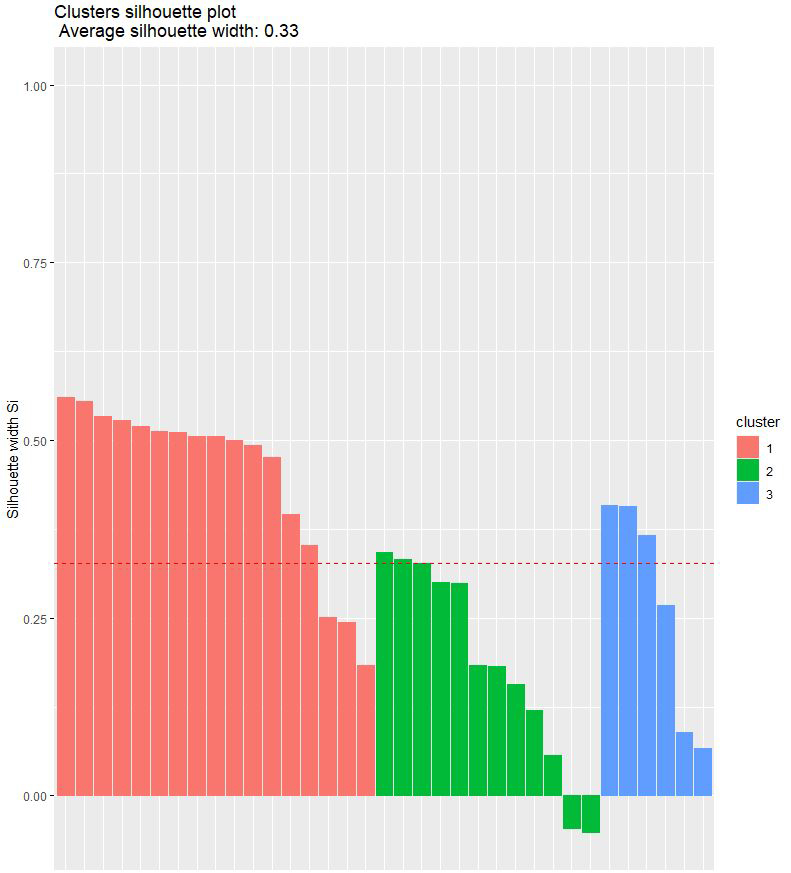
Vemos los jugadores que hay en cada uno de los grupos:
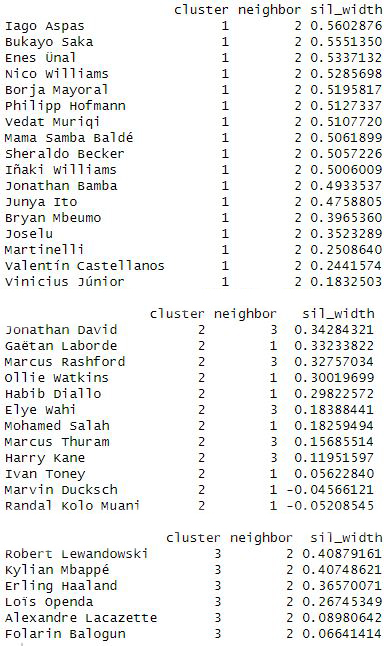
- Accediendo a cada cluster individual vemos como en el cluster 2 tenemos a Kolo Muani y Marvin Ducksch, que que podrían estar en otro cluster si se formaran más.
- En los clusters 1 y 3 parece que todos los jugadores están bien ubicados.
ANÁLISIS DE CLUSTERIZACIÓN JERÁRQUICO
Una vez terminado el proceso de clusterización NO jerárquico de K-Medias, vamos a contrastarlo con el método de clusterización jerárquico.
Cargando diferentes métodos de clusterización (como por ejemplo el «Average» o el «Complete»), el siguiente paso es el de hacer el cálculo de la distancia cophenetic con todos estos métodos para saber cual de ellos es el que mejor explica la distancia real entre los jugadores.
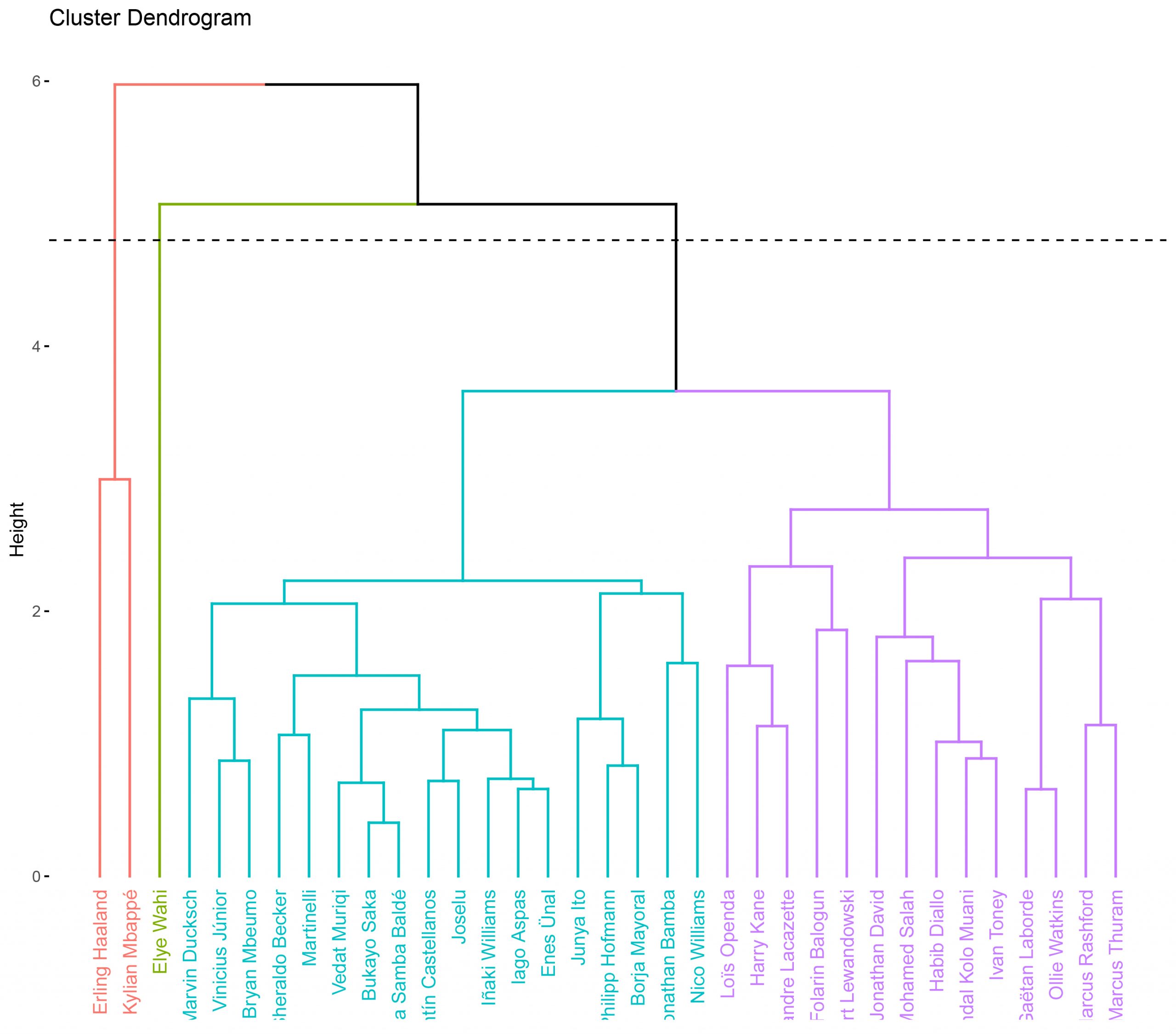
REPRESENTACIÓN DE UN DENDOGRAMA
Vamos a representar un dendograma y, segun el resultado obtenido en el paso anterior en el cálculo de la distancia Cophenetic, usaremos: La distancia euclídea y el método «Average».

- Podemos ver como ya podemos ir distinguiendo diferentes grupos o conglomerados.
- Hay algunos jugadores que están muy diferenciados, los «jefes», Haaland y Mbappé, y también vemos a Elye Wahi separado del resto, otro delantero joven (20 años) que ha tenido una temporada espectacular con el Montpellier, marcando 19 goles.
- Bukayo Saka, del Arsenal y Mama Samba Baldé, del Troyes, parece que son los jugadores más similares.
- También vemos mucha similitud entre, por ejemplo, Iago Aspas, del Celta y Enes Ünal, del Getafe.
A partir de este dendograma, voy a generar otro indicando directamente cuántas particiones quiero (en este caso, 4).
También se puede visualizar usando las dos dimensiones con PCA, como antes en las visualizaciones con K-Medias:
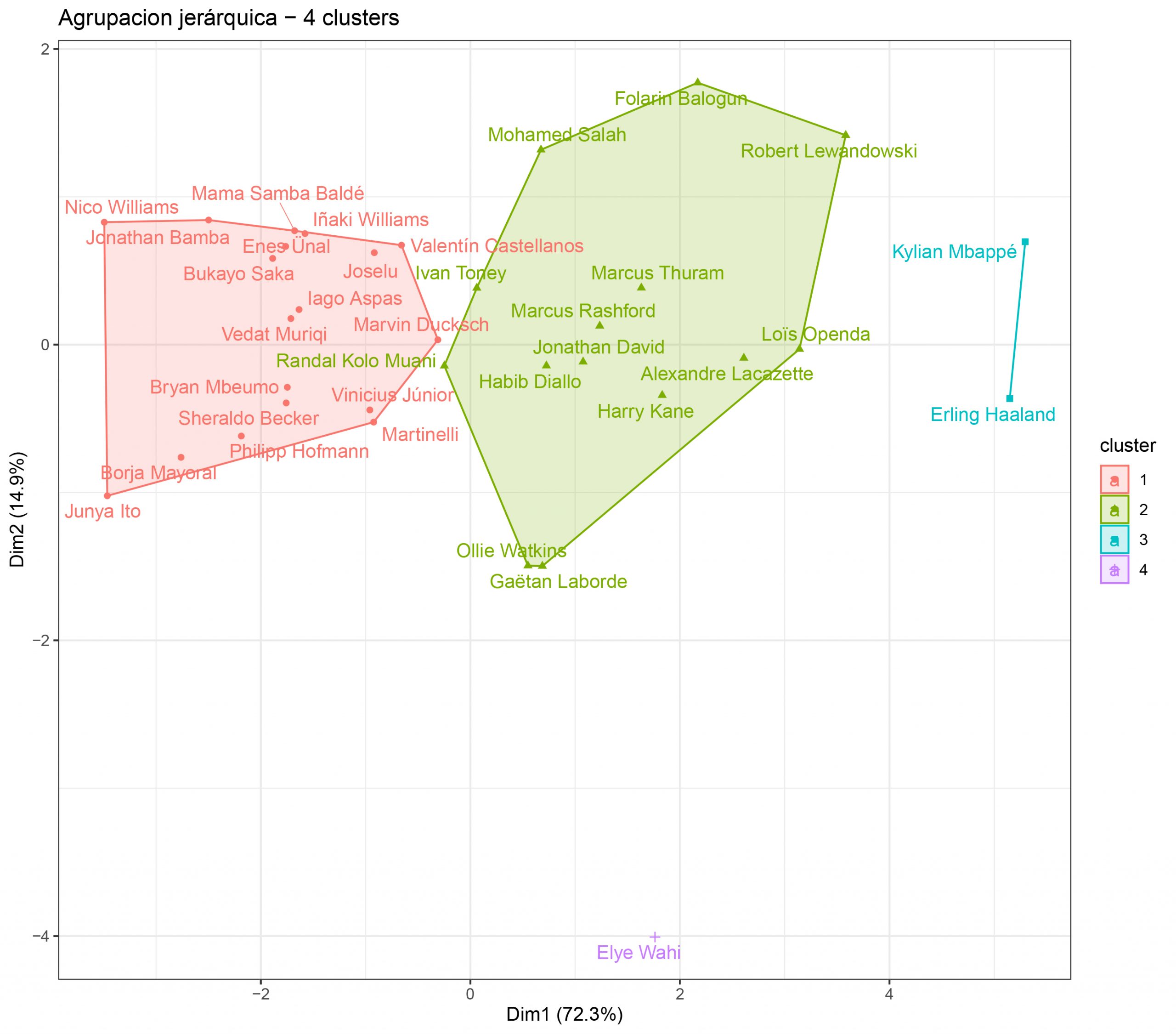
Vemos como con cuatro clusters Elye Wahi se queda como cluster independiente, mientras que tenemos otro cluster formado únicamente por Haaland y Mbappé.
Si hacemos una prueba con 3 clusters, que fueron los que elegimos para K-Medias…
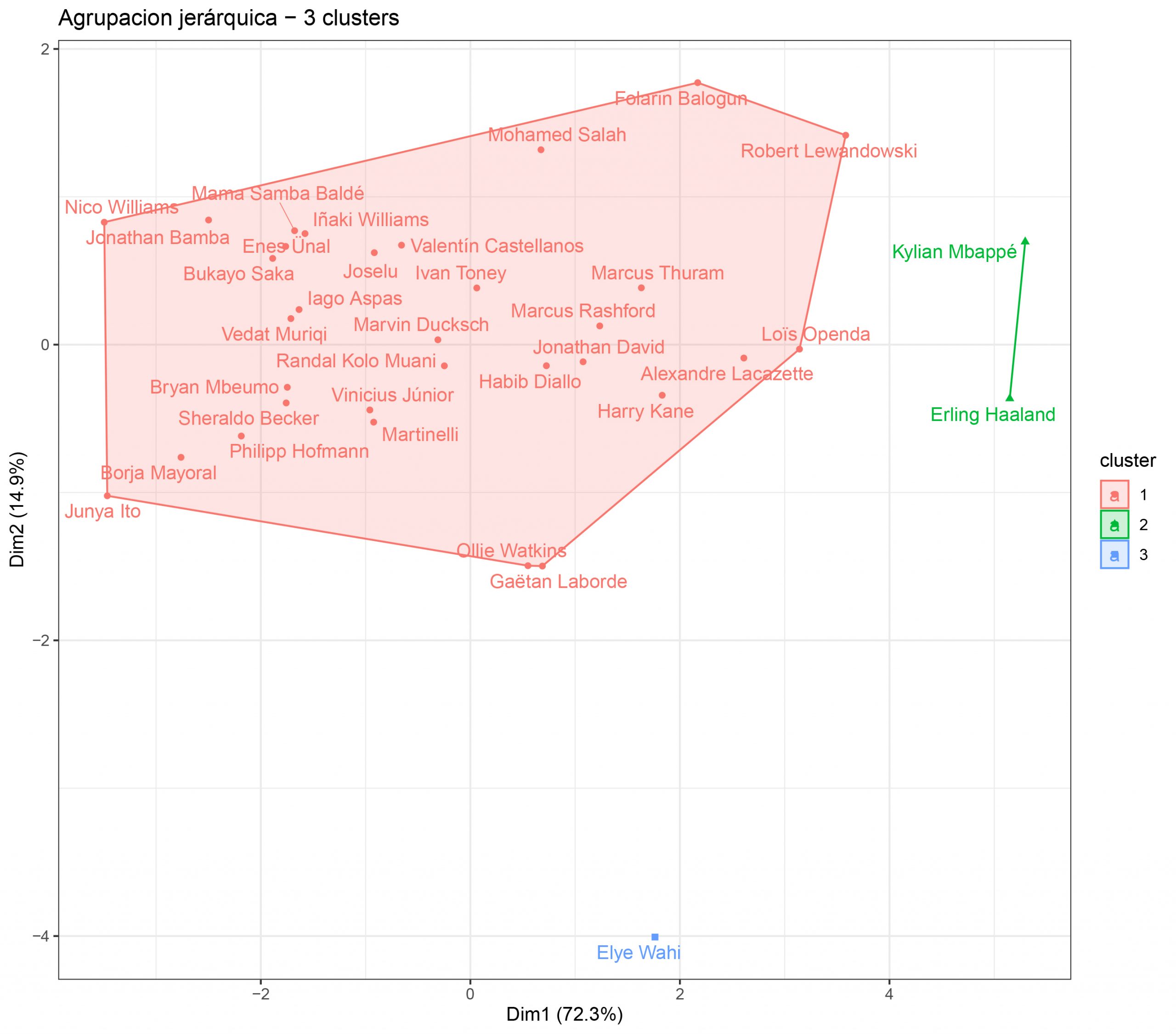
El resultado no convence… Se han unido los cluster 1 y 2 y no parece que sea muy real tener en el mismo grupo a jugadores como Junya Ito, Iñaki Williams o Mayoral con Harry Kane, Lewandowski o Rashford.
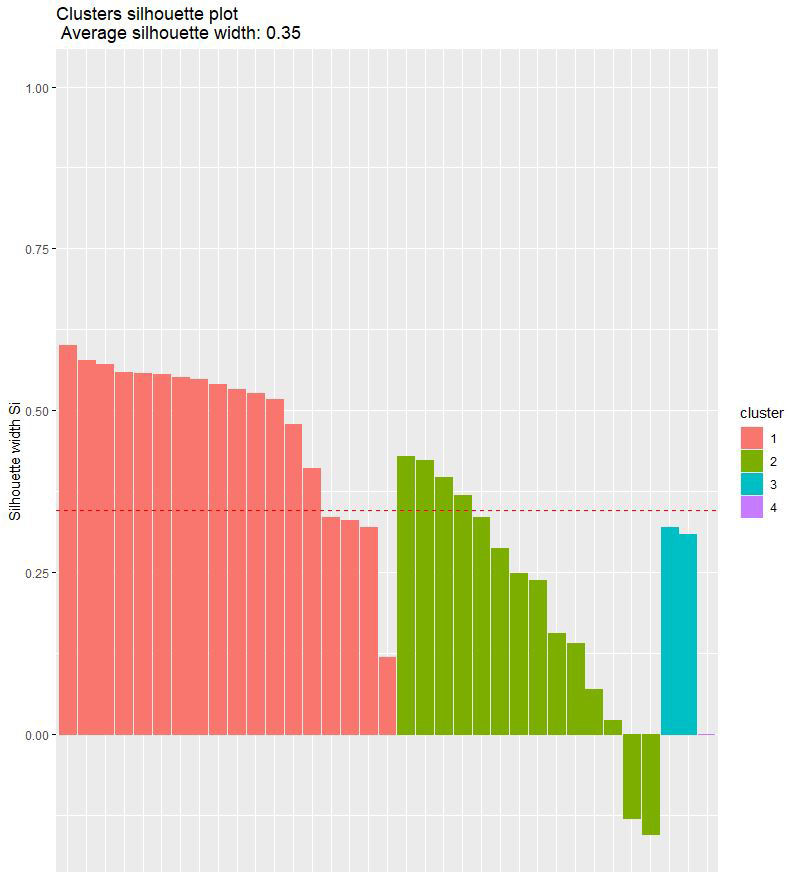
Al igual que con el método de K-Medias, aplico el método de la Silueta para ver si están bien clasificadas las observaciones o particiones.
Vemos los jugadores que hay en cada uno de los grupos:
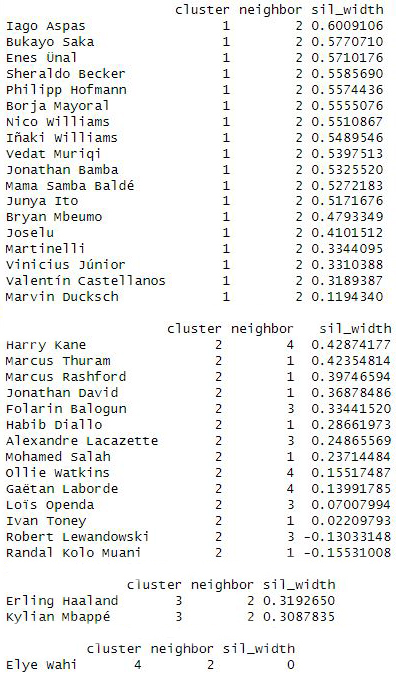
- Accediendo a cada cluster individual vemos como en el cluster 1 los jugadores parece que están bien posicionados.
- El clusters 2, Lewandowski y Kolo Muani podrían estar en otro cluster si se formaran más.
- El cluster 3 lo forman Haaland y Mbappé.
- El cluster 4 solo lo forma Elye Wahi.
DIFERENCIAS ENTRE LOS MODELOS
- En el método jerárquico hemos añadido un cluster más y, mientras que en K-Medias Haaland y Mbappé estaban en el mismo grupo que otros grandes delanteros como Lacazette o Lewandowski, aquí los tenemos a ellos solos como integrantes del cluster 3.
- Elye Wahi se quedó como cluster independiente, mientras en K-Medias estaba en el 2.
- El método de la silueta es muy similar en ambos, 0,35 para el jerárquico y 0,33 para K-Medias.
¿Qué método es mejor?… la respuesta es que uno no es mejor que el otro, dependerá de los datos que tengamos, así pues, basado en el conjunto de datos utilizado para este trabajo, me inclinaría por K-Medias, ya que me parece que hace una separación más homogénea.