Nowadays, in the player scouting process, it’s very common to use a similarity index to show which players are likely to be most similar to each other. This process is particularly useful for teams with tight budgets, as they will usually need to “discover” new players and this similarity index can help them.
This process is important, but the purpose of this exercise is not only to look for the similarity of a player, but also to look for the similarity between teams, because in order to try to make the right choice of a player it’s important to ask ourselves a question… Would this player “x” be the right choice for my team?
In this exercise we will try to find the most similar player to Alexis Sánchez, a player who played for Olympique Marseille last season. To do so, we will first start with a similarity index created to discover the most similar players to him and then we will generate another one, this time of teams, to check if any of the players obtained also play in a team similar to OM.
Obviously, even if there’s a player who has a high level of similarity, but does not play in a team very similar to OM, it should not be a main reason to discard him, but this step will give us one more argument to choose one player over another.
It’s also important to clarify that, although this exercise is designed to show similarity indexes based on the Cosine and Euclidean distances, when we are going to carry out this exercise in a real case, we must choose only one of them and bet on it.
The data used for both players and teams has been obtained from the fbref website and corresponds to the entire 2022-2023 season.
This exercise is done entirely in R, the data cleaning process in Python and the visualisations with Power BI and Python.

SELECTION OF THE SAMPLE TO EVALUATE PLAYERS
As always, the first thing to do is to make a selection of the sample we are going to use, in this case, having most of the metrics provided by fbref, we will filter by competition, position and minutes played.

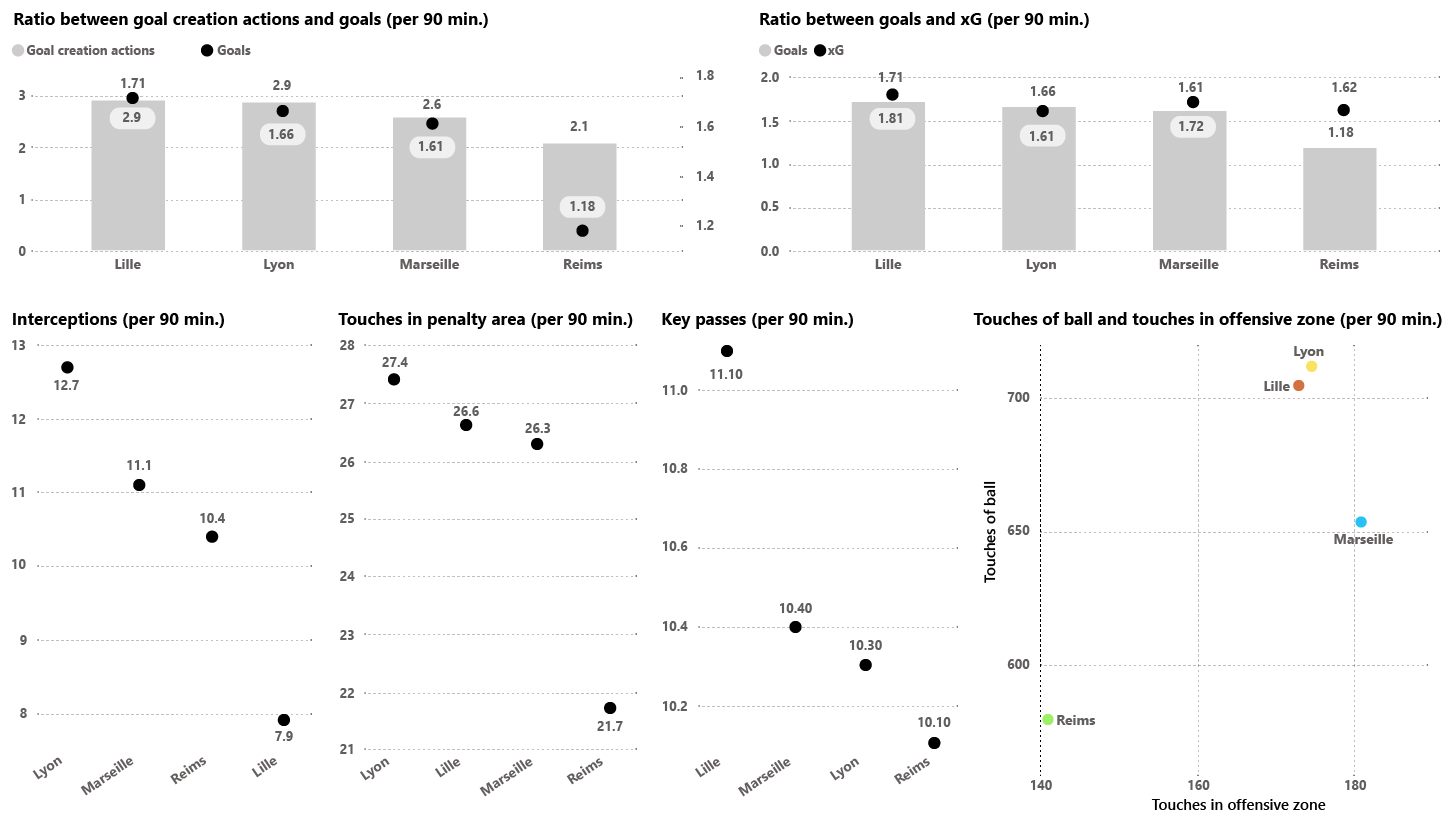
Afterwards, the metrics that are considered relevant to evaluate the strikers will be chosen.
APPLYING SIMILARITY ALGORITHM
To summarise without showing all the elements of the code, we will calculate the Cosine distance and the Euclidean distance in R.
When do we say that a player is similar to another one? Well, we can say that two players are similar when they are close in distance between them, so, to apply this similarity algorithm, we have to calculate the distance we want to use, in this case, the Euclidean distance and Cosine distance.
And what are the differences between Euclidean distance and Cosine distance?
EUCLIDEAN DISTANCE
We can say that the Euclidean distance is the common distance, which tells us whether two players are similar when the values of their metrics are close.
COSINE DISTANCE
We must consider that it’s possible that the Cosine distance tells us that two players are similar even if their metrics are not similar and, explained a bit quickly without going into too much depth, this is because this Cosine distance concludes that if player A had the same opportunities or the same minutes played as player B, he could be closer in distance than a player who does have more similar metrics but who has accumulated more participation.
Having calculated the distances and applied the similarity algorithm in R, it’s time to see what the results show.
PLAYER RESULTS
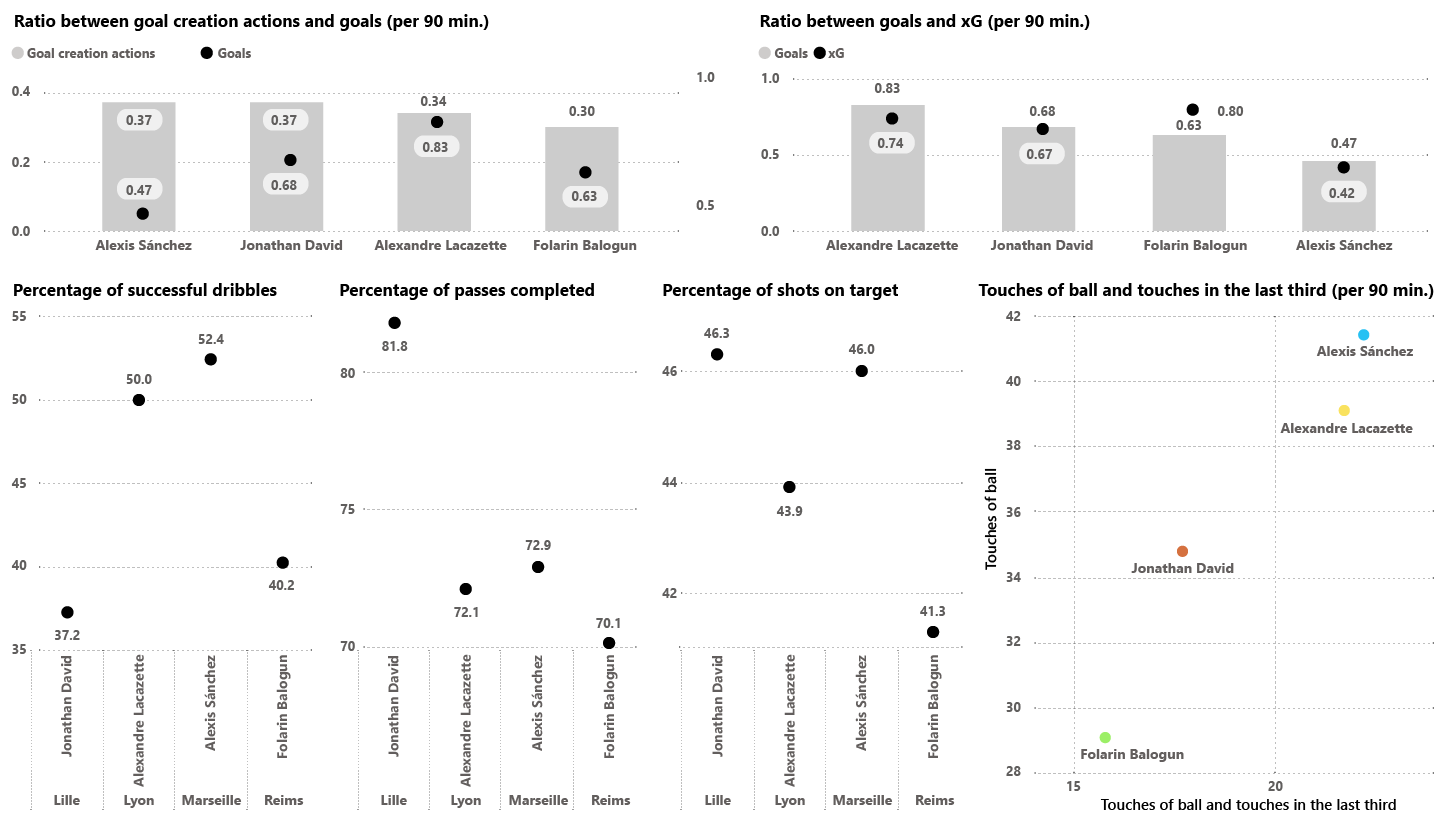
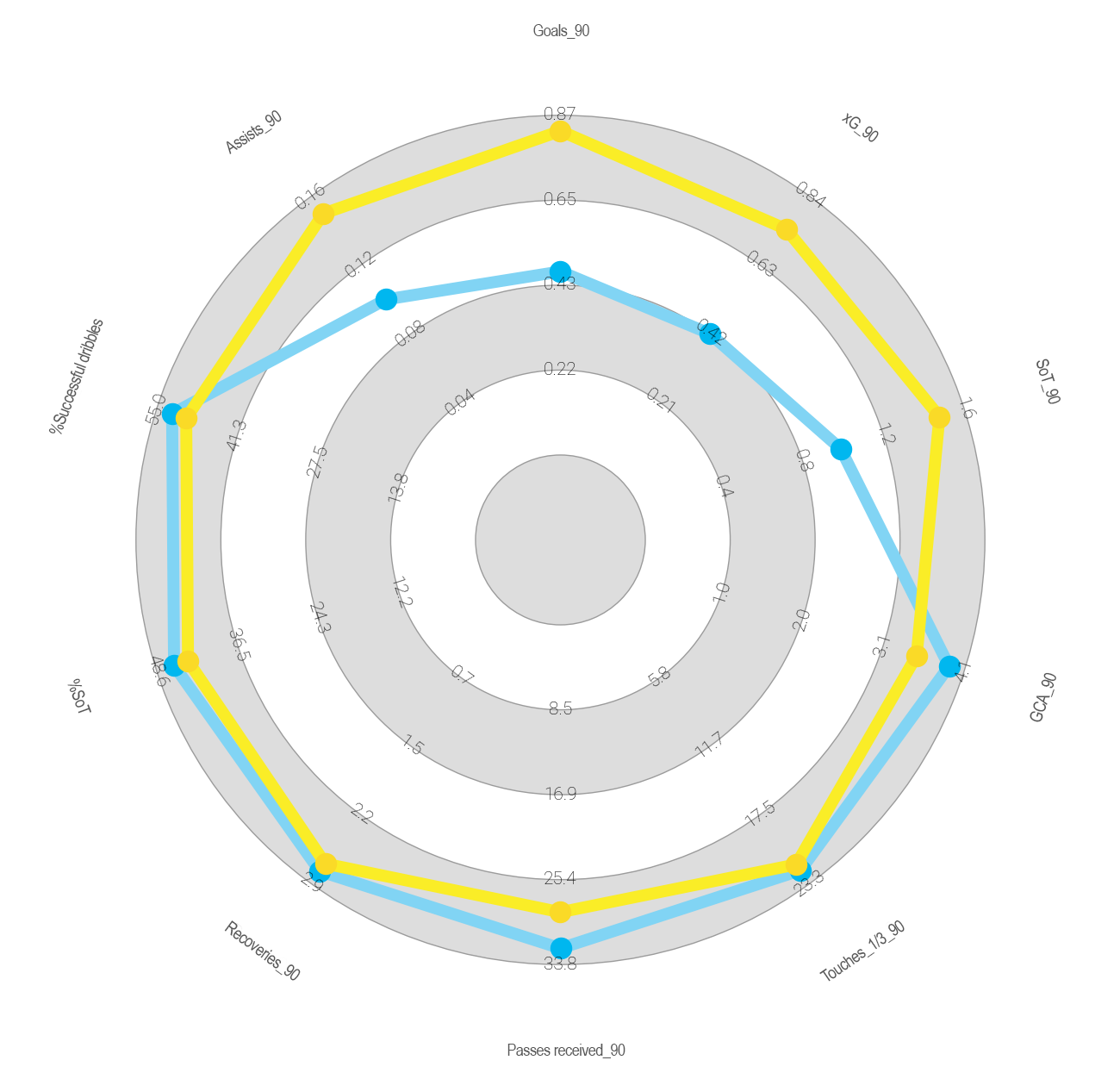
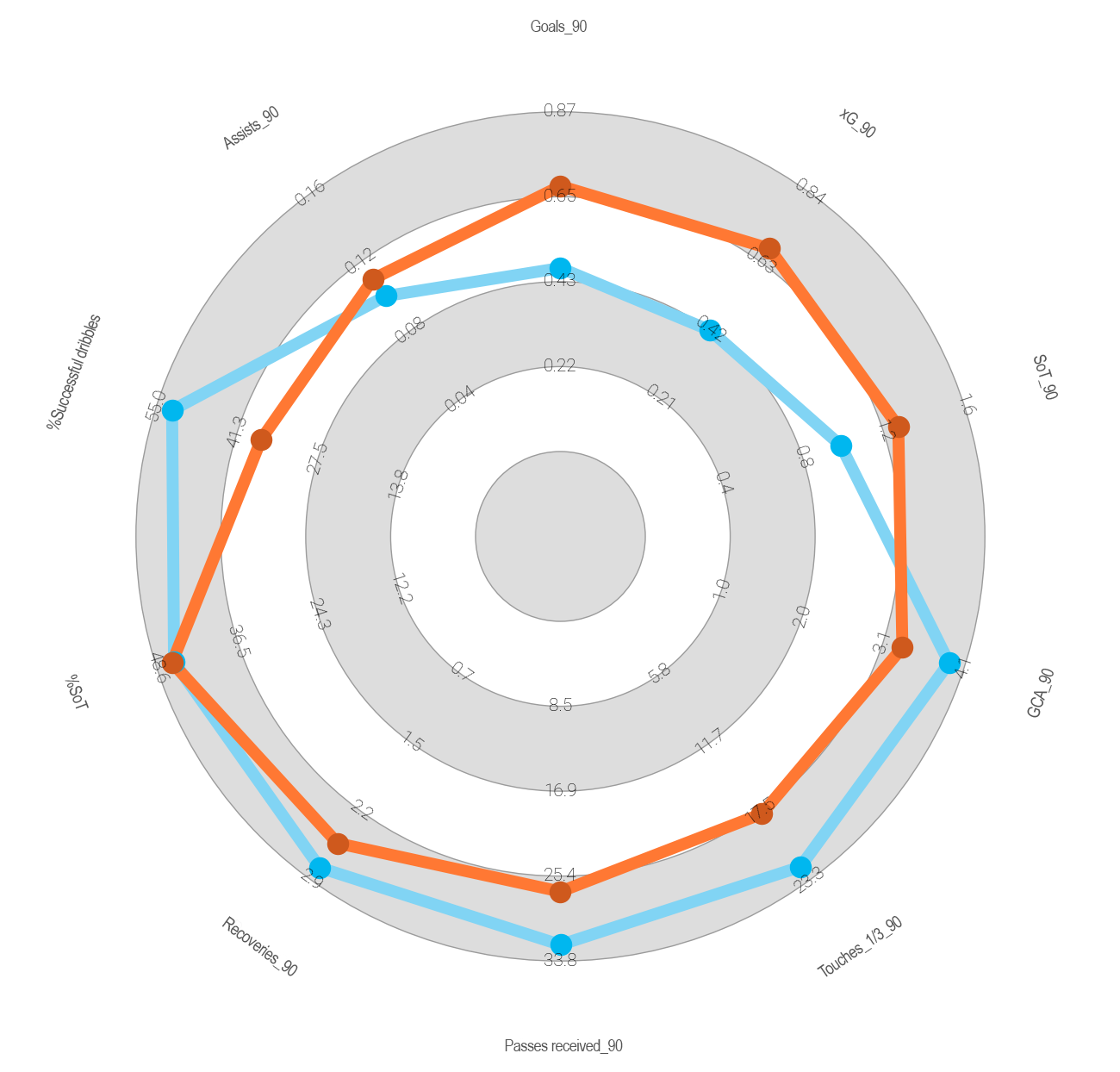
To obtain the result with both distances and, considering the characteristics of the player we want to analyse, I’ve selected different metrics that include both offensive and other defensive and possession metrics, all standardised per 90 minutes (I do not name each metric in order not to make the article too long).
The result with the Cosine distance shows us the 10 most similar players:
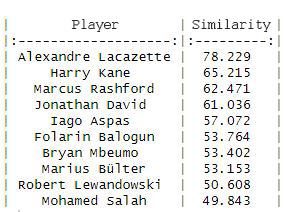
The result with Euclidean distance shows us the 10 most similar players:
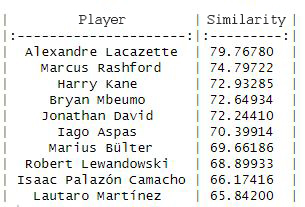
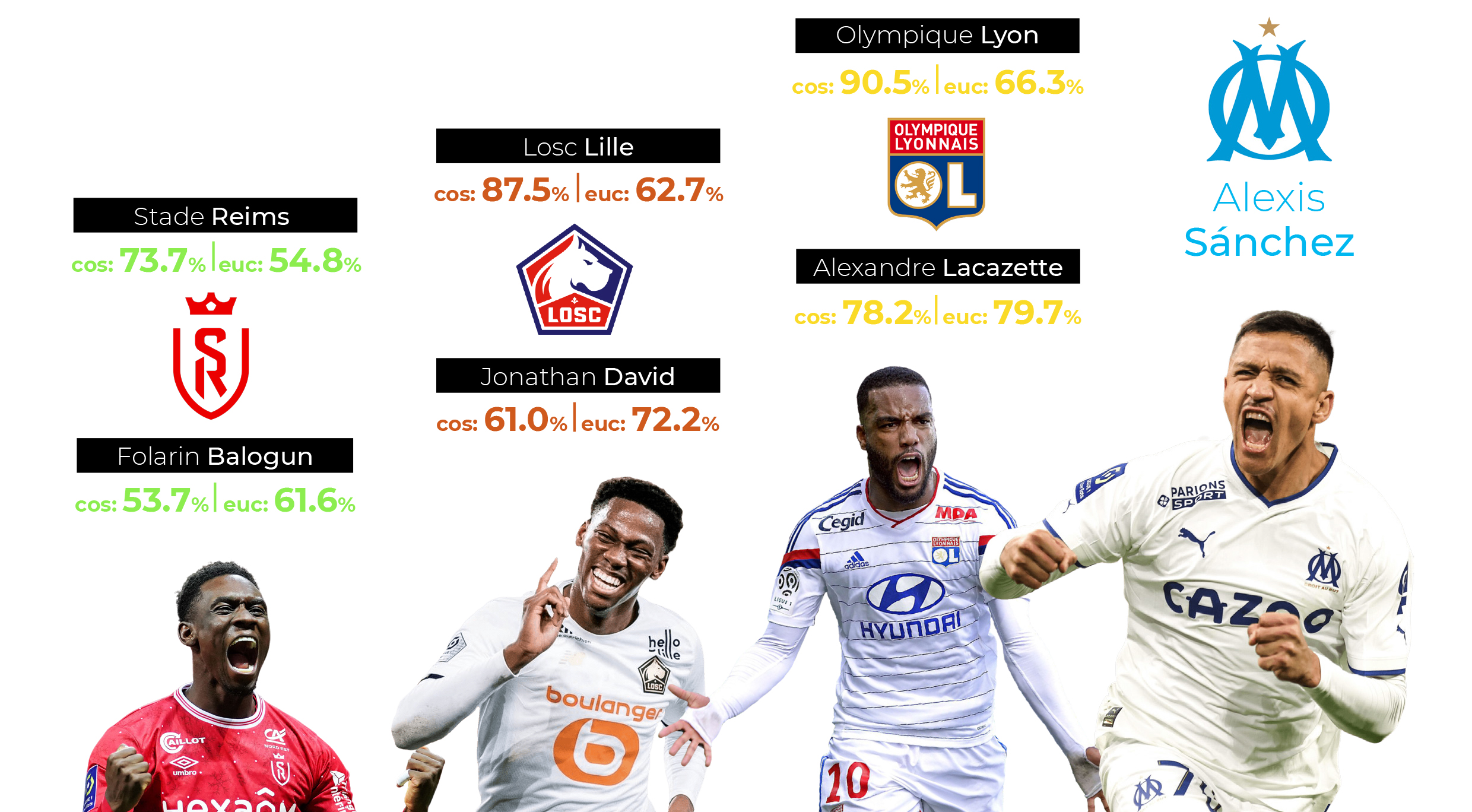
As you can see, on this occasion there are no significant differences between the two distances and Alexandre Lacazette of Olympique Lyon leads the ranking with a similarity index of 78.2% and 79.7% respectively.
Once we have these results, let’s repeat the whole process, but this time taking the data from the teams.
TEAM RESULTS
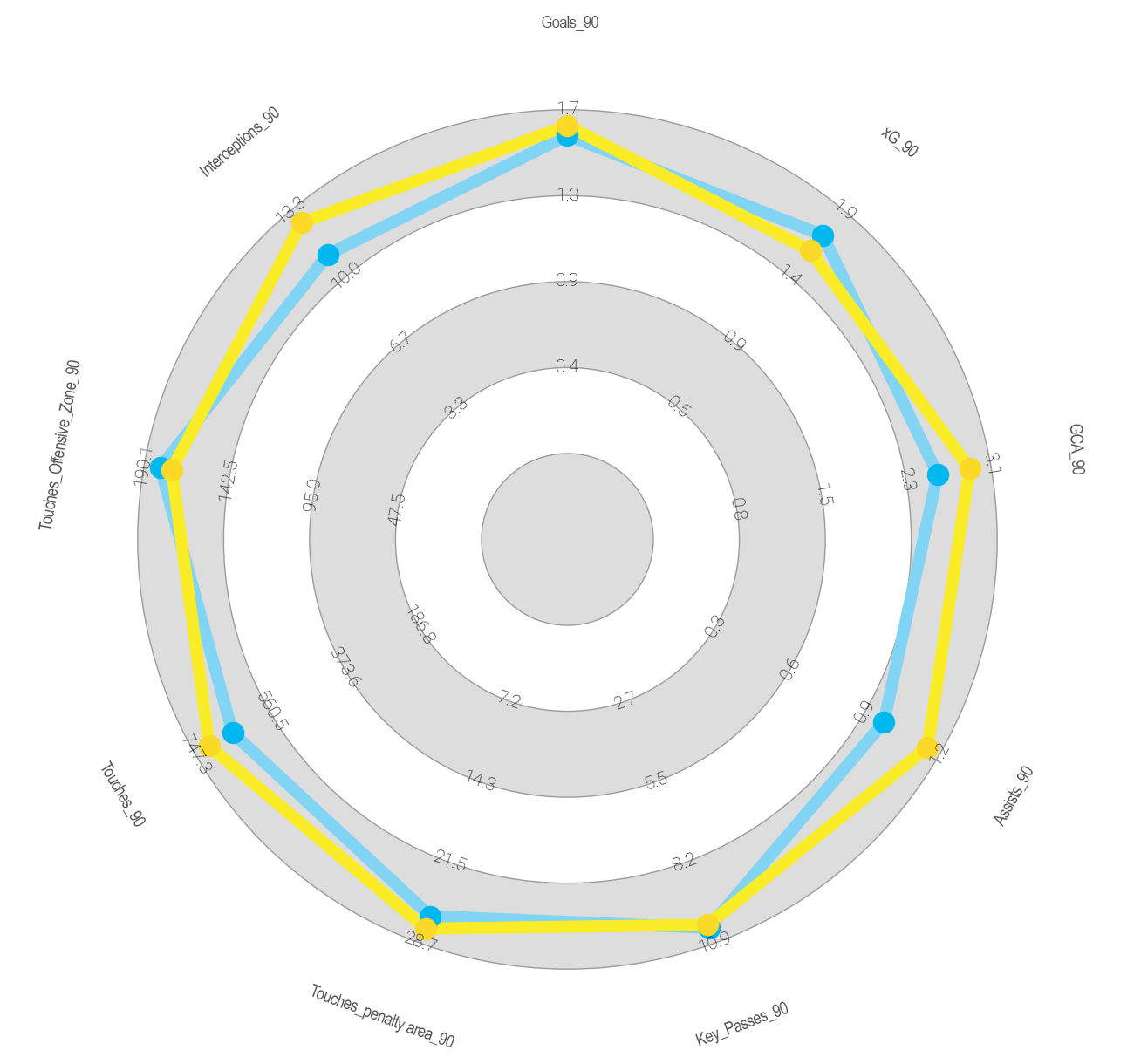
To obtain the result with both distances and, considering that the purpose is to obtain an index of the similarity of the teams on a global level, I’ve selected metrics that cover all aspects of the game (I do not name each of the metrics in order not to make the article too long).
The result with the Cosine distance shows us the 10 most similar teams:
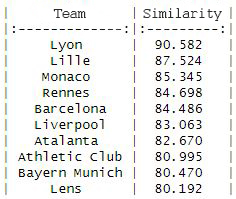
The result with Euclidean distance shows us the 10 most similar teams:
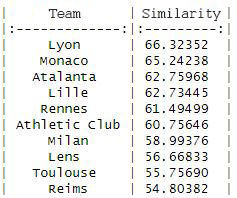
We also note that the team most similar to OM coincides in both metrics and the rest, in general terms, only suffer slight differences, moving up or down a few places.
There are only three teams that don’t repeat in the top ten in both metrics: Milan, Toulouse and Bayern Munich.
WHAT WAS OLYMPIQUE DE MARSEILLE’S CHOICE?
OM’s choice to replace Alexis Sanchez was Pierre-Emerick Aubameyang, a Gabonese player from Chelsea who played a total of 563 minutes in only 16 matches.
These statistics make comparing the two players more complicated and, obviously, having made a sample selection with players who had played more than 2,500 minutes, this player does not appear, but, if we were to apply the Coseno distance with him in it (I think that in this case it is the only distance that could be valid), he would be very far from being a very similar player to Alexis Sanchez (he would appear in the 243rd position with a similarity index of 34.4%).
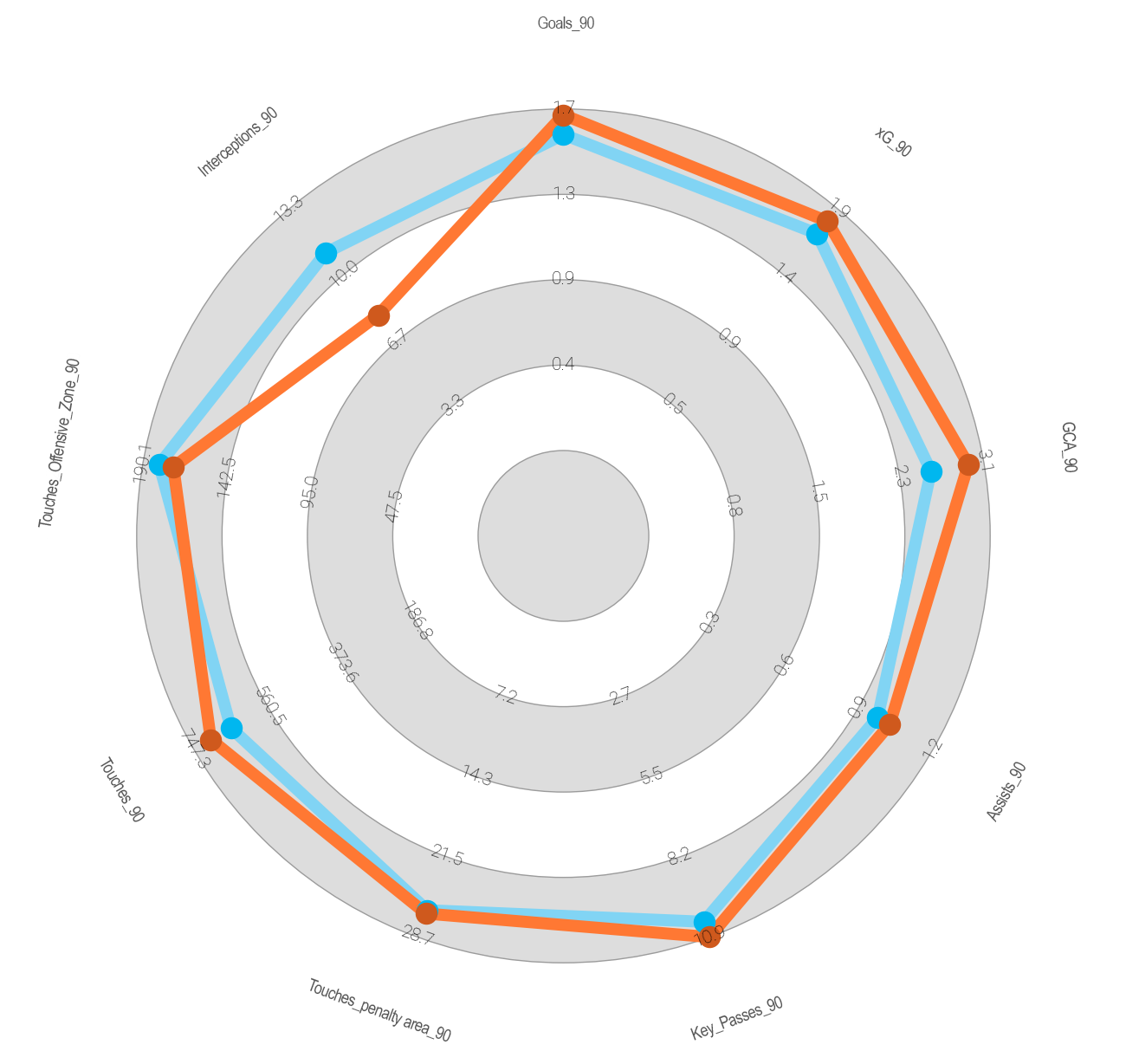
But… what about his team? Having done the similarity indexes with all the global statistics of the teams, here we can see where Chelsea stands in relation to OM.
If we look at the Cosine similarity, we see that Chelsea is in 23rd position with 67.6%, while in the Euclidean similarity it appears in 22nd position with 43.6%.
The choice of a player can be based on many aspects, perhaps in this case the economic aspect was the main one (he arrived free at OM), but as this exercise is based on finding a player similar to Alexis Sanchez (although we don’t know if that was actually OM’s idea when signing him), what is clear is that the data does not support the choice of Aubameyang as a replacement similar to Alexis Sanchez.

CONCLUSIONS:
- We can see that in first position at both distances, Olympique Lyon is the team most similar to OM, so the choice of Lacazette as a replacement for Alexis Sanchez would be fully justified.
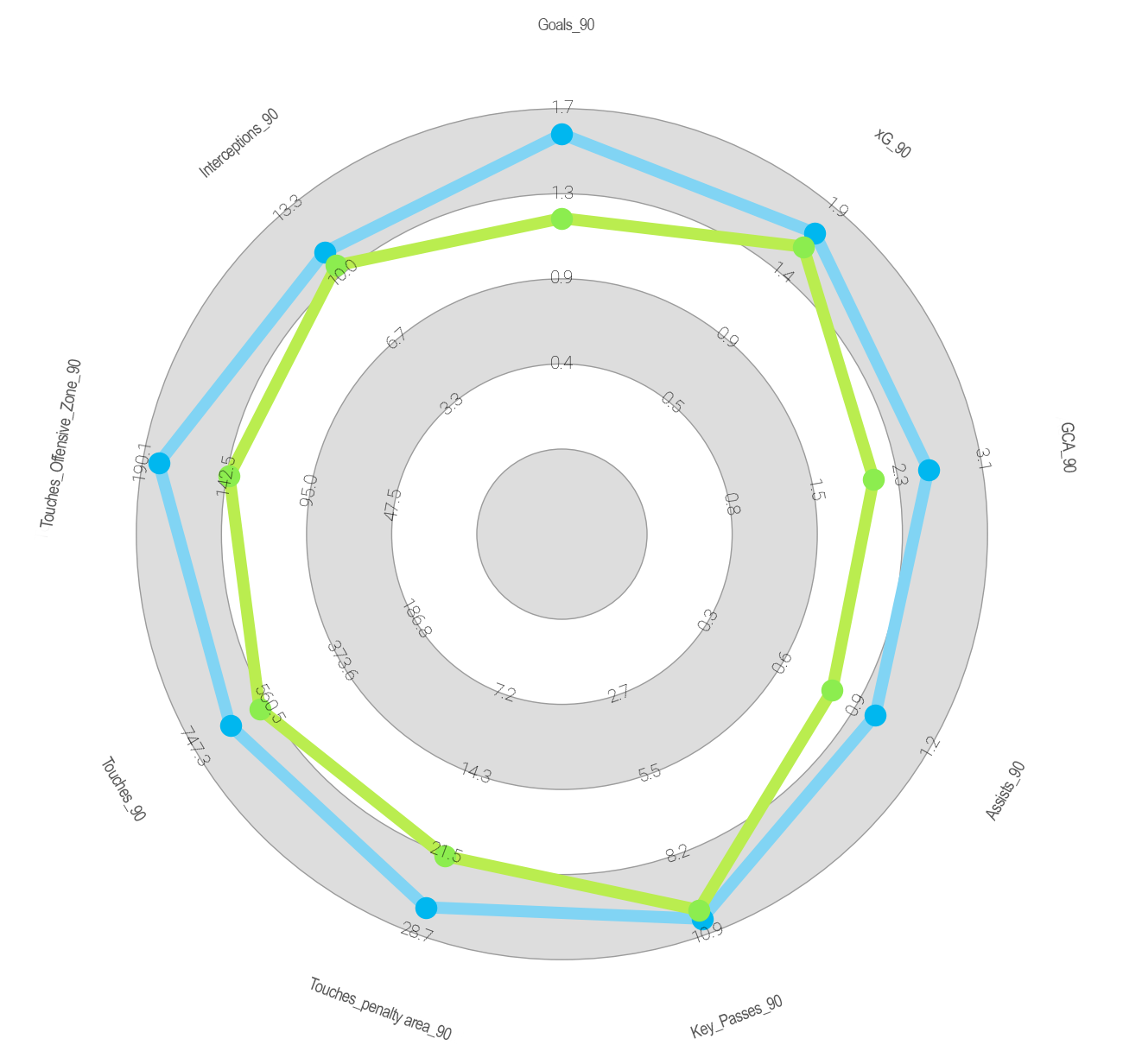
- We can also note the Canadian Jonathan David, who appears very high in the player similarity index (61% and 72.2% respectively) and, in addition, his team appears in second place in the Cosine similarity index (with 87.5%) and in fourth place in the Euclidean index (with 62.7%).
- Another option to explore further would be Folarin Balogun who, although he does not appear in the top ten in the Euclidean distance (16th position with 61.6%), he does appear well ahead in the Cosine distance (sixth position with 53.7%). Stade de Reims, the club he played last season (he has recently been transferred to Monaco) does not appear in the top ten in the Cosine index (18th position with 73.7%) and appears in tenth position in the Euclidean index (with 54.8%).
- Players such as Rashford, Kane, Salah or Lewandowski are not valued as possible substitutes as they are not affordable for OM.
- As a final conclusion, and to reiterate what was said in the introduction, although this exercise is based on the calculation of both distances, to create a similarity index we must study which metric is more convincing and only bet on one of them.
PLAYER VISUALISATIONS



TEAM VISUALISATIONS